
Google和幼儿有什么共同之处?两者都需要学习良好的聆听技巧
Google和幼儿有什么共同之处?两者都需要学习良好的聆听技巧
投稿人和专利探险家戴夫戴维斯回顾了最近发表的一篇文章,该文章建议谷歌将实体分组并利用他们的关系来倾听更好的多部分问题答案。

在第六届学习代表国际会议上,Google AI的研究人员Jannis Bulian和Neil Houlsby 发表了一篇论文,阐述了他们正在测试的改进搜索结果的新方法。
虽然发表论文当然不意味着这些方法正在被使用,甚至会被使用,但当结果非常成功时,这可能会增加可能性。当这些方法与谷歌正在采取的其他行动相结合时,几乎可以肯定。
我相信这种情况正在发生,而这些变化对于优化专家(优化)和内容创建者来说意义重大。
发生什么了?
让我们从基础开始,并且看看正在讨论的内容。
据说一张图片胜过千言万语,所以让我们从纸张的主要图像开始。

这张图片绝对不值一千字。事实上,没有这些字眼,你可能很迷茫。您可能想像一个搜索系统看起来更像是:
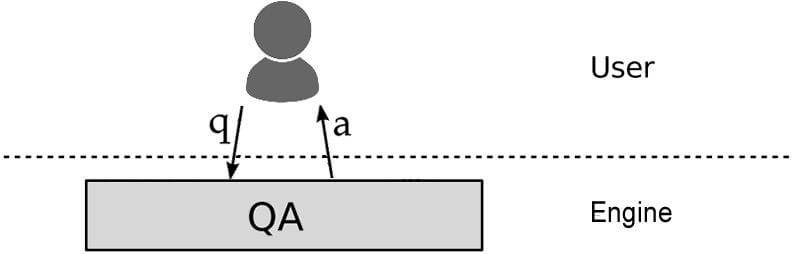
在最基本的形式中,搜索系统是:
- 用户提出问题。
- 搜索算法解释问题。
- 算法应用于索引数据,并提供答案。
我们在第一张图片中看到的,它说明了论文中讨论的方法,却有很大的不同。
在中间阶段,我们看到两部分:重构和总结。基本上,这个新流程发生的是:
- 用户向积极提问问题(AQA)代理的“重新配置”部分提出问题。
- “重构”阶段带着这个问题,并且使用下面讨论的各种方法创造一系列新问题。
- 这些问题中的每一个都被发送到“环境”(我们可以松散地将其视为核心算法,就像您今天会想到的那样)以获得答案。
- 每个生成的查询的答案在“Aggregate”阶段提供给AQA。
- 获胜的答案被选择并提供给用户。
看起来很简单,对吧?这里唯一真正的区别是产生多个问题和一个系统,找出哪个是最好的,然后提供给用户。
哎呀,有人可能会争辩说,这是已经发生的算法评估一些网站,并共同努力找出查询的最佳匹配。轻微的扭曲,但没有革命性的,对吗?
错误。这篇论文和方法还有很多不仅仅是这张图片。所以让我们继续前进。现在是时候添加一些...

机器学习
这种方法的真正威力来自于机器学习的应用。以下是我们需要询问的有关初始故障的问题:
系统如何从各种问题中进行选择?
哪个问题产生了最佳答案?
这是它变得非常有趣的地方,结果令人着迷。
在他们的测试中,布鲁恩和豪尔斯比开始了一系列“危险!”的问题(如果你看节目,你就知道这些问题真的是答案)。
他们这样做是为了模拟人脑需要推断正确或错误反应的场景。
如果您对游戏节目“Jeopardy!”不熟悉,请点击此处快速剪辑以帮助您了解“问题/答案”概念:
从论文:面对复杂的信息需求,人们通过重新构建问题,发布多次搜索和汇总响应来克服不确定性。受到人类提出正确问题的能力的启发,我们向学员展示学习如何为用户执行此过程。
这是算法提出的“危险!”问题/答案之一。我们可以看到问题如何转化为查询字符串:
旅行似乎不是这个巫师和一次性外科医生的问题; 星界投影和传送是没有问题的。
这不是一个容易回答的问题,因为它需要收集各种数据,并且还要解释自己经常隐晦的问题的格式和背景。事实上,没有人发布“危险!” - 就像问题一样,我不认为Google目前的算法能够返回正确的结果,这正是他们正在寻求解决的问题。
Bulian和Houlsby用“Jeopardy!”编写了他们的算法 - 就像问题一样,并将一个成功的答案计算为给出正确或错误答案的答案。该算法是从来没有意识到的,为什么一个答案是正确的还是错误的,所以它没有给出任何其他信息来处理。
由于缺乏反馈,算法无法通过任何其他方式学习成功指标,而不是获得正确答案。这就像在一个类似于现实世界的黑盒子里学习一样。
他们从哪里得到问题?
测试中使用的问题来自哪里?他们被送到Reformulate阶段的“用户”。一旦问题被添加,流程:
- 从查询中删除了停用词。
- 将查询置为小写。
- 添加了wh-短语(谁,什么,何地,何时,为什么)。
- 增加了释义的可能性。
对于释义,该系统使用联合国平行语料库,该语料库基本上包含1100多万个与六种语言完全一致的短语。他们制作了各种英文到英文的翻译器,可以调整查询但保持上下文。
结果
所以这就是所有这一切降落我们的地方:

训练完系统后,结果非常壮观。他们开发和训练的系统击败了所有变体并大幅提高了性能。事实上,做得更好的唯一系统是人类。
以下是最终生成的查询类型的一小部分示例:

他们所开发的系统能够准确地理解复杂而复杂的问题,并通过训练以惊人的准确度产生正确答案。
那么,戴夫?这对我有什么帮助?
你可能会问为什么这很重要。毕竟,在搜索和持续改进方面不断发展。为什么这会有什么不同?
最大的区别是它对搜索结果意味着什么。谷歌最近还发布了一份ICLR会议的文件,建议Google可以根据其他内容制作者提供的数据制作自己的内容。
我们都知道,仅仅因为写了一篇论文,并不意味着搜索引擎实际上正在实施这个概念,但让我们暂停一下,以便了解以下情况:
- Google有能力提供自己的内容,而且内容写得很好。
- Google对确定正确答案的能力非常有信心。事实上,通过调整其功能,它可能会超越人类。
- Google有多个例子可以让用户留在自己的网站上,并通过点击布局和内容更改的搜索结果。
随着这一切堆积如山,我们需要问:
- 这会影响搜索结果吗?(它可能会。)
- 它会阻碍网站管理员的内容制作工作吗?
- 它会限制我们的内容向更大的公众传播吗?
再次,仅仅因为论文被发表,并不意味着内容将被实施; 但谷歌是获得的在超过人体的方式与语言理解复杂的细微差别的能力。Google也有兴趣让用户留在谷歌地产上,因为在一天结束时,他们首先是一家出版公司。
你能做什么?
你做同样的事情,你一直做。推销您的网站。
无论您是优化进入有机结果的前10名还是优化语音搜索或虚拟现实,都会销售相同数量的蓝色小部件。你只需要适应,因为搜索引擎结果页面(SERP)变化很快。
我们在这里看到的方法提出了一个重要的主题,每个对优化(优化)感兴趣的人都应该密切关注,这就是实体的使用。
如果您查看由Bulian和Houlsby创建的系统生成的以上查询集,您会注意到一般情况下,越精确地理解实体之间的关系,答案就越好。
事实上,具体措辞是无关紧要的。完全部署后,系统不需要使用您或我理解的文字。值得庆幸的是,它们使我们能够看到,通过将实体及其关系进行分组,使得以这些关系为基础的答案更加可靠,可以实现成功。
如果你只是理解实体,那么这里有一段介绍概念和涵义的内容。我保证你很快就会看到它们之间的联系,而当我们进入下一代搜索领域时,你需要关注这个领域。
{kind=link}